 |
The Southwest Data Display and Analysis System (SDDAS) is a flexible multi-mission/multi-instrument software system intended to support space physics data analysis. The utility of the system relies on the availability of low-cost workstation technology, an operating system that runs on different hardware platforms (UNIX), and the proliferation of the Internet. The development of the SDDAS is driven from the bottom up by the user community rather than by government organizations. An interesting characteristic of the SDDAS is that it allows data in distributed archives, from many different satellites and other sources to be displayed and analyzed using a diverse set of graphical applications. Data can be ordered and delivered over the Internet independent of the archive location and the nature of the archive storage. Rather than emphasizing the indexing of data by ancillary characteristics, the SDDAS stresses the ability to visualize and analyze data quickly. The SDDAS has provided the developers with many useful lessons learned in the arena of space physics data systems. The developers feel that a strong case can be made that large, centralized facilities offering a fixed set of abilities will not adequately support space science in the 1990s and beyond. The SDDAS approach is adaptable to advances in computer technology, thus giving the scientist a toolbox that can bridge the gap between data and scientific insight. |
There have been many NASA discipline specific data systems developed and used with varying degrees of success. All these systems were intended to support ongoing analysis of spacecraft data and, in a few cases, interdisciplinary studies. Most were conceived with a specific user community in mind. This paper presents a short tour of an alternative approach to supporting space science, the Southwest Data Display and Analysis System (SDDAS). SDDAS development was from an orthogonal direction when it is compared to other NASA funded systems. Its development has been bottom up rather than top down, user driven rather than organization driven. SDDAS development costs have been minor in terms of funding and resources. The SDDAS was designed to evolve in order to take advantage of new technology and changing user requirements. Two key concepts form the foundation of the SDDAS. With the right tools, a great deal of science can be done without writing programs. The second key idea is that tools and access are one. This Taoist sounding statement embodies the philosophy of the SDDAS designers: one must be able to access data and do something with it immediately. Hence, the SDDAS emphasizes interactive analysis and keeping the globally distributed data archive immediately accessible. It also requires certain types of metadata be stored with the data because it is needed to convert raw data to science units and to make meaningful displays. |
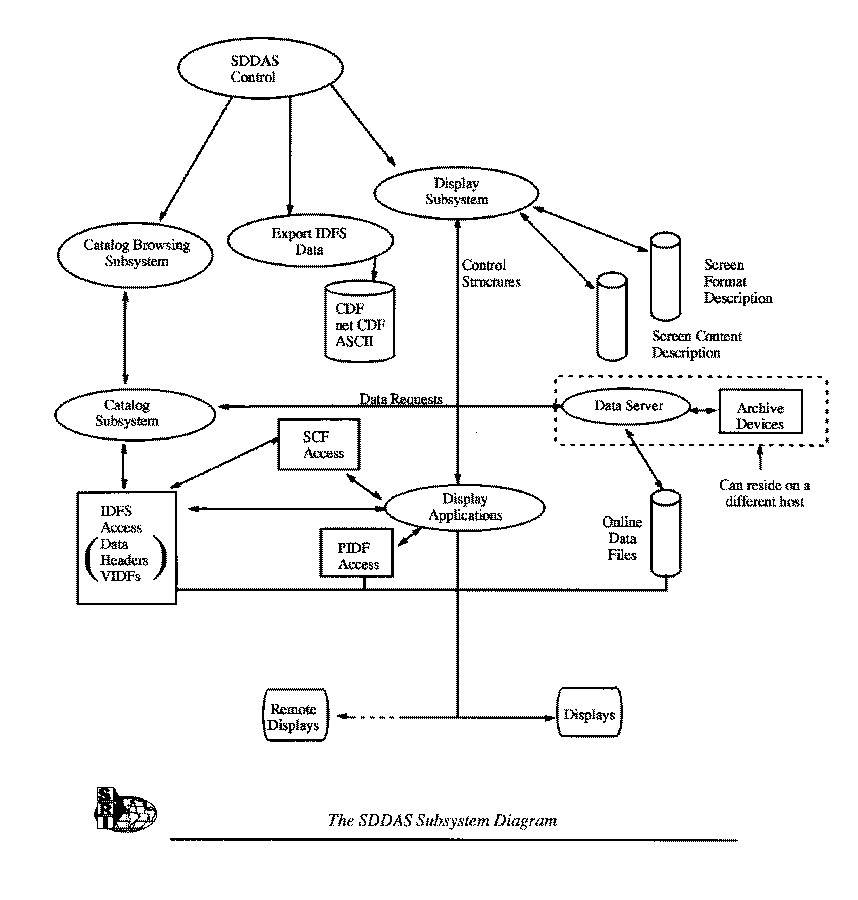
The SDDAS is built on a client/server model used by many systems. The client side contains the graphical and analysis tools, catalog subsystem, and user interface. The server side maintains the data archive and provides data granules (files) to the client side. |
The SDDAS Subsystem Diagram , illustrates the process relationships within the SDDAS software. Each subsystem has a specific graphical user interface (GUI) defined for interactions. A common set of buttons and pull-down menus is used across each subsystem. The graphical tools are the heart of the SDDAS. All are oriented towards examining space physics data, although other kinds of data can be displayed if it is stored in a format called the Instrument Data File Set (IDFS). The IDFS is discussed later in this document. The catalog subsystem is particularly simple in that all entries are organized by time and are located using time as the independent variable. The sole purpose of the catalog subsystem is to identify which data files cover a given time period and make sure that these files are accessible by each of the analysis subsystems. Making files available may require moving files from a remote archive to local storage. Unlike systems which use database management software, a file is the smallest granule of data which can be located by the catalog. Other characteristics of the data can not be used to extract a "slice" of data from an archive. The trade-off is simplicity and speed; data slicing is done by each analysis subsystem. |
The heart of the SDDAS is the ability to produce graphical exposition (line plots, spectrograms, images, xy spectral plots, and contour plots) of the data as well as mathematical analyses without writing software. Each application has an extensive set of menus to provide the user with the means to tailor what is displayed and analyzed. Additionally, the user may combine different types of plots on the display using a composition tool that allows great flexibility in building complex displays. The SDDAS requires X-window support on the target machine, as specific types of graphical display devices are no longer directly supported. The applications can also write various graphical languages and formats for those who need a hardcopy (e.g., Postscript, GIF). Each application has the ability to save all configuration information into a layout file. Thus allows complex parameter sets to be created and then reused quickly for subsequent analysis work. These files can be exchanged between users as a mechanism for collaborative data analysis. |
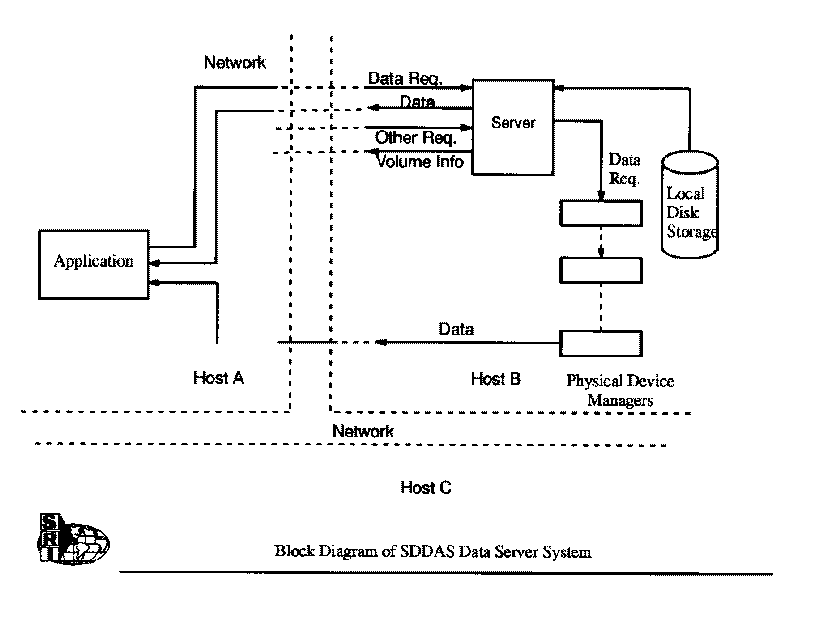
The server subsystem provides the interface between the data archive and all client subsystems. The server provides the external interface to the device-specific storage management programs provided at each archive site. In this way, the nature of archive devices is hidden from the end user and each archive site can use the available storage subsystem.. The server uses the BSD socket interface to communicate with clients. TCP is used because it is widely supported, although any connection-oriented stream protocol that guarantees reliable data delivery will do. The server attempts to set the TCP window size to a large value in order to optimize data transfers. SwRI has developed device interface programs for many mass storage devices. It is easy to add user written interface programs for additional storage devices. The data server will function using only disk data storage if no "deep archive" devices are available. The server supports access to an administrator-specified directory tree on local disk storage, similar to an FTP server set up for anonymous access. |
The Instrument Data File Set (IDFS) is a set of file written in a prescribed format which contains data, timing data, and meta-data. IDFS development and evolution has been underway for the past decade, overlapping with the other storage and representation methods like CDF, HDF, and FITS. The impetus behind the IDFS is the need to maintain a certain metadata parameters with the data in order to make the displays like those in the examples possible. The two key tasks supported by the IDFS are the conversion of telemetry values to engineering and scientific units and the registration of each data sample to a given point in time. In magnetospheric physics time tagging is very important because data are commonly acquired from many different sensors at the same time. Simultaneous measurements on different satellites or between a satellite and ground stations are increasingly important. Even small timing errors may completely confound a proper physical interpretation of the data. There are three kinds of information that go into an IDFS for a given instrument: the telemetry of the sampled data, ancillary or engineering telemetry, and a large quantity of information not necessarily from the spacecraft. This last class of data can contain all sorts of calibration and timing factors. The full details are much too involved to be covered in this overview. Given the fact that many spacecraft now have instruments that operate in nondeterministic ways due to data adaptive mode changing, the IDFS can be exceedingly detailed. However, once data is stored in an IDFS, a library of access routines allows the SDDAS to extract most any needed parameter. The three required files within an IDFS are: data file, header file, and the virtual instrument description file (VIDF). A virtual instrument is a data stream of one measured parameter or a group of closely related parameters and it may optionally contain calibration data. The data file contains the data in its most basic form, such as telemetry values. The header file contains timing information about the data and is mainly useful when the data are non-contiguous in time. The VIDF contains text parameter descriptions, calibration tables, and a great deal more meta-data. |
An additional metafile, called the Plot Information and Description File (PIDF), is used as a mechanism to further parameterize the creation of displays. This optional file contains various limit values and labels that must be associated with a particular virtual instrument. Default values are stored in the PIDF, also. An important feature of the SDDAS is the ability to perform user-specified transformations on the data before it is displayed or plotted. The user describes each algorithm using a symbolic language that is placed in a Special Computations File (SCF). The PIDF file can then reference the SCF and the transformed data will appear as a "data source" exactly like data residing on disk. We envision a basic set of transformations being pre-coded and provided along with the SDDAS to the science community. |
|
[Home]
[About]
[Links]
[Sample Plots]
[SDDAS Install] [User's Guide] [Programmer's Guide] [Tutorials] [Contact] |
{kind=link}
{kind=link}